WebUI: A Dataset for Enhancing Visual UI Understanding with Web Semantics
palette Abstract
Modeling user interfaces (UIs) from visual information allows systems to make inferences about the functionality and semantics needed to support use cases in accessibility, app automation, and testing. Current datasets for training machine learning models are limited in size due to the costly and time-consuming process of manually collecting and annotating UIs. We crawled the web to construct WebUI, a large dataset of 400,000 rendered web pages associated with automatically extracted metadata. We analyze the composition of WebUI and show that while automatically extracted data is noisy, most examples meet basic criteria for visual UI modeling. We applied several strategies for incorporating semantics found in web pages to increase the performance of visual UI understanding models in the mobile domain, where less labeled data is available: (1) element detection, (2) screen classification and (3) screen similarity.
smart_toy Data Collection
We implemented a parallelizable cloud-based web crawler to collect our dataset, consisting of a crawling coordinator server, a pool of crawler workers, and a database service. The crawler worker used a headless framework to interface with the Chrome browser and employed heuristics to dismiss certain popups. The crawling policy encouraged diverse exploration, with the coordinator organizing upcoming URLs by hostname and selecting them using assigned probabilities. The crawler workers visited web pages using multiple simulated devices, capturing viewport and full-page screenshots, as well as some other web semantic data including:
- Accessibility trees: The accessibility tree is a tree-based representation of a web page that is shown to assistive technology, such as screen readers. The tree contains accessibility objects, which usually correspond to UI elements and can be queried for properties (e.g., clickability, headings). Compared to the DOM tree, the accessibility tree is simplified by removing redundant nodes (e.g., div tags that are only used for styling) and automatically populated with semantic information via associated ARIA attributes or inferred from the node's content.
- Layouts and computed styles: For each element in the accessibility tree, we stored layout information from the rendering engine. Specifically, we retrieved 4 bounding boxes relevant to the "box model": (i) the content bounding box, (ii) the padding bounding box, (iii) the border bounding box, and (iv) the margin bounding box. Each element was also associated with its computed style information, which included font size, background color and other CSS properties.
dataset Dataset Overview
The WebUI dataset contains 400K web UIs captured over a period of 3 months and cost about $500 to crawl. We grouped web pages together by their domain name, then generated training (70%), validation (10%), and testing (20%) splits. This ensured that similar pages from the same website must appear in the same split. We created four versions of the training dataset. Three of these splits were generated by randomly sampling a subset of the training split: Web-7k, Web-70k, Web-350k. We chose 70k as a baseline size, since it is approximately the size of existing UI datasets. We also generated an additional split (Web-7k-Resampled) to provide a small, higher quality split for experimentation. Web-7k-Resampled was generated using a class-balancing sampling technique, and we removed screens with possible visual defects (e.g., very small, occluded, or invisible elements). The validation and test split was always kept the same.
shelf_position UI Modeling Use Case 1: Element Detection
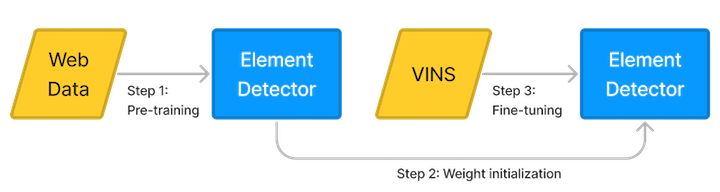
We applied inductive transfer learning to improve the performance of a element detection model. First, we pretrained the model on web pages to predict the location of nodes in the accessibility tree. Then, we used the weights of the web model to initialize the downstream model. Finally, we fine-tuned the downstream model on a smaller dataset consisting of mobile app screens
hdr_strong UI Modeling Use Case 2: Screen Classification

We applied semi-supervised learning to boost screen classification performance using unlabeled web data. First, a teacher classifier is trained using a “gold" dataset of labeled mobile screens. Then, the teacher classifier is used to generate a “silver" dataset of pseudo-labels by running it on a large, unlabeled data source (e.g., web data). Finally, the “gold" and “silver" datasets are combined when training a student classifier, which is larger and regularized with noise to improve generalization. This process can be repeated (however, we only perform one iteration).
landscape UI Modeling Use Case 3: Screen Similarity
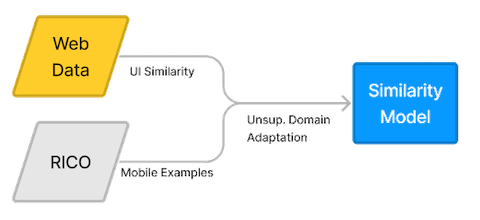
We used unsupervised domain adaptation (UDA) to train a screen similarity model that predicts relationships between pairs of web pages and mobile app screens. The training uses web data to learn similarity between screenshots using their associated URLs. Unlabeled data from Rico is used to train an domain-adversarial network, which guides the main model to learn features that transferrable from web pages to mobile screens.
quick_reference_allReference
@article{wu2023webui,
title={WebUI: A Dataset for Enhancing Visual UI Understanding with Web Semantics},
author={Jason Wu and Siyan Wang and Siman Shen and Yi-Hao Peng and Jeffrey Nichols and Jeffrey Bigham},
journal={ACM Conference on Human Factors in Computing Systems (CHI)},
year={2023}
}
partner_exchange
Acknowledgements
This work was funded in part by an NSF Graduate Research Fellowship.
This webpage template was inspired by the BlobGAN project.